Having an established workflow is important to me, as it helps me cover all the bases of a project and feel confident that my concept has a sound logic. (Stefanie Posavec, 2016)
はじめに
情報可視化にはある程度の決まった流れがあります。このおおまかな流れは、情報可視化を行う時に考慮すべきことと言い換えることもできます。
考慮すべきことをあらかじめ把握しておくことは、作業の恣意性を減らすことができる一方で、新しいことを試す時の参照点にもなります。創造的なものは往々にしてルールを破ることから生まれますが、ルールを知らないとそれを破ることはできないのです。
情報可視化の6ステップ
情報可視化を6つのステップに分けて説明します。
- 問いの設定:データを通して答えたい問いを決めます。
- データの用意:データの取得・確認・前処理・管理をします。
- データの探索(探索的可視化):データの特徴をおおまかにつかむために、探索的可視化を行います。
- 仮説の設定:データの探索から、問いに対する仮説を立てます。
- データの分析:データ分析を通して仮説を検証し、問いに対する答えを導き出します。統計的な手法が有効であることが多いです。
- データの説明(説明的可視化):問いとその答えを、人に伝えるために可視化します。目的と受け手を考えて、人が理解しやすいようにデザインすることが重要です。
この6ステップは直線的なプロセスではなく、複数のステップを行ったり来たりすることになります。
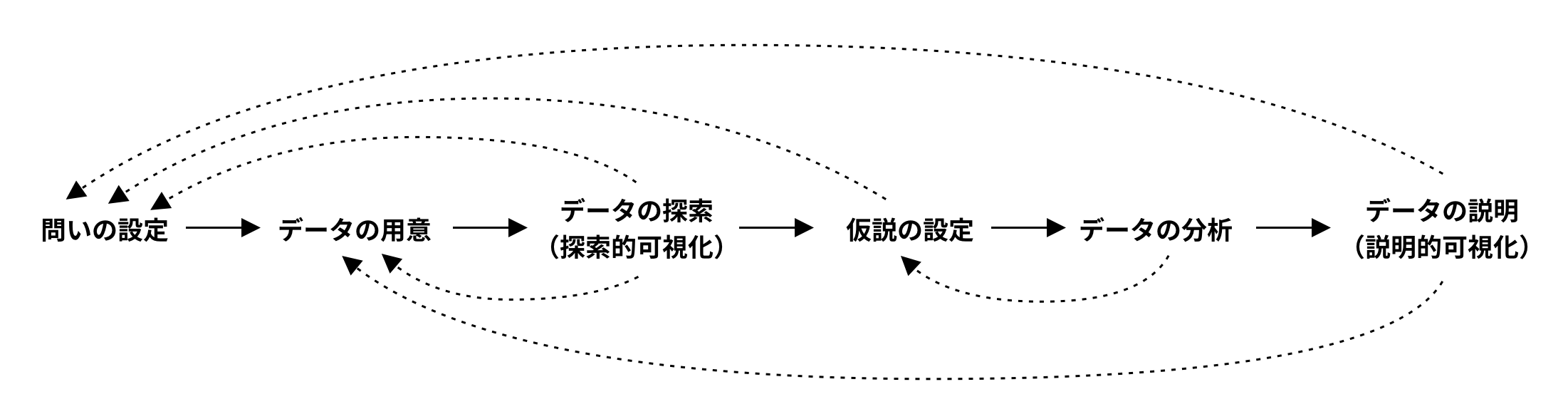
この講義では、全ステップを概観しますが、特にデータの用意に焦点を当てます。
問いの設定
問いを設定することが重要な最初のステップです。データがあるから可視化するわけではありません。
もちろん、最初から明確な問いが設定できるとは限りません。データの収集と探索が進むにつれて問いが変わったり、より具体的になったりするのはよくあることです。繰り返しになりますが、情報可視化は反復的なプロセスなのです。
データの用意
データは情報可視化の原材料です。様々な方法で取得することができますが、データの品質と信頼性を精査することが重要です。また、適切な前処理と管理も有益な情報を得るためには重要です。
データの取得
- 既存のデータを使う
- 関係者の提供
- 誰かがすでに持っているデータをもらう
- オープンデータのダウンロード
- さまざまな機関や団体が、自由に使えるデータを公開している
- 関心のあるデータを探してみると面白い
- API (Application Programming Interface)
- ウェブサービスによっては、データセットではなくデータセットを取得するための接続口を提供している
- SNSなどのデータはAPIを通して取得できることが多い
- ウェブスクレイピング
- ウェブサイトで公開されている情報を、スクリプトによって収集することができる
- APIが提供されている時はAPIを優先する
- 関連する法律やサイトの利用規約に気をつける
- 法律や利用規約の範囲内でも、倫理的に問題にならない範囲で行う
- 関係者の提供
- 新たにデータを生成する(実験・調査・記録)
- 特定の現象をシミュレーションする
- 質問紙調査などの社会調査を行う
- 健康に関する情報を測定機器を使って記録する
- 映像や音声から文字を起こす、など
既存のデータを使うにせよ、新たにデータを生成するにせよ、重要なのは目的に沿った良いデータを集めることです。また、「データは作るもの」だという意識も重要です。提供されていないデータを収集してデータセットを作ることはもちろん、提供されているデータセットであってもデータ分析の目的に沿って出力されているわけではないため、データの取捨選択や加工が必要です。分析者のデータの作り方によって、データの有用性が決まるといえます。
データの確認
データを取得したら、まずは生データを眺め、データの特性と状態を把握することが重要です。
ここでは、データ型、データのサイズ(量と範囲)、データの状態(品質と代表性)について確認します。
データ型
- テキスト(Textual)
- 質問紙の自由記述(「ご意見があればどうぞ」)への回答
- 新聞記事、論文、小説
- 画像や音声の文字起こし、など
- 名義(Nominal)
- 質問紙回答者の出生国
- レストランのメニュー
- 映画のジャンル
- オリンピックの競技種目、など
- 順序(Ordinal)
- 質問紙の文にどの程度同意できるかの回答(「非常にあてはまる」から「全くあてはまらない」など)(リカート尺度)
- TシャツのXSからXXLまでのサイズ
- オリンピックのメダルの金・銀・銅、など
- 間隔(Interval)
- BMI (Body Mass Index)
- 天気予報の気温
- 場所の経緯度、など
- 比例(Ratio)
- 質問紙回答者の年齢
- 天気予報の雨量
- オリンピックの走り幅跳びの成績、など
他に考慮すべきこととして、離散値・連続値、線形スケール・非線形スケール(対数スケールなど)があります。
データのサイズ(量と範囲)
データの全変数の量的な属性を検討します。例えば、次のようなことを確認します。
- 量的変数(間隔と比率)の最小値と最大値はなにか?
- 数値はどのような形式になっているのか?(桁数、小数点記号など)
- 質的変数(名義と順序)には、どれだけの異なり値があるのか?
- テキストデータの最大文字数と最小文字数はなにか?
他にも検討できる側面はたくさんあります。できるだけデータを全面的に把握してください。 以下に、よく使われる統計的な手法を列挙します。
- 度数分布:量的変数の値の分布
- 度数:質的変数のそれぞれの値の頻度
- 中心傾向の指標:平均値、中央値、最頻値など
- 変動性の指標:
- 最大値、最小値、範囲
- パーセンタイル
- 標準偏差、など
データの状態(品質と代表性)
データの品質に関しては、例えば以下のことを確認します。
- 欠損値:空白のセルは値がないのか(ゼロ/無)、測定しなかったのか(N/A)
- エラー値:明らかにおかしな値(セルがずれているなど)
- 不統一:表記、測定単位、値の形式
- 重複
- 期限切れの値:現時点で不正確だと思われる値(人の年齢など)
- 異常なシステム文字や改行
- 先頭や末尾の余分な空白
- 日付のフォーマット
データの代表性に関する確認は、データそのものだけではなく、分析の目的にも関わってきます。以下のことを確認しましょう。
- データは本当に分析したい事象をあらわしているか?
- 取得方法はデータにどのような影響をあたえているか?
- 母集団と標本にはどのような差がありそうか?
データの前処理
データの確認で見つけた問題への対応をはじめ、データを分析しやすいように処理します。欠損値や異常値への対処方法は様々なものが考案されていますが、目的に適った方法を選びましょう。
重要なのは、意思決定を明示することと一貫性を保つことです。
- クリーニング:データの品質の問題を解決する
- データの作成:計算や変換を通して新たなデータを作る
- データの拡張:分析に必要なデータを新たに入手する
データの管理
データを適切に管理することも、データの用意の重要な一部です。これには、名前管理、構成管理、仕様書作成、バージョン管理などが含まれます。
名前管理
データファイルや各データ項目に適切な名前をつけることで、データの詳細な定義を見なくても何のデータなのかが分かるようになります。
例えば、data.csvと名付けるかわりに、covid-19_new_cases_202210.csvなどと名付けるようにしましょう。
命名規則を作成し、規則の使用を徹底することをおすすめします。
構成管理
構成管理とは、どのファイルをどのフォルダに格納するか、各フォルダをどのような階層に置くかを決めて管理することです。プロジェクトごとに、データはこのフォルダ、ソースコードはこのフォルダ、スライドはこのフォルダ、論文やレポートはこのフォルダ、というような規則を作成しましょう。プロジェクトの最上位階層にテキストファイルを作ってこの規則を書いておくとよいです。
下記は構成管理の一例です。
|- project_A
|- README.txt: フォルダとファイルの説明
|- data: 加工済みデータ
|- log: 加工前の元データ
|- code: コード
|- slide: スライド
|- paper: 論文・レポート
|- figures: 画像
|- tmp: 一時的に保存しておくもの
|- project_B
|- ...
|- ...
|- ...
仕様書作成
データそのものに加えて、データに関する情報をまとめておくとスムーズにデータを利用することができます。
例えば、次のようなものです。
| カラム | カラムの説明 | 型情報 | 値の説明 | NULL | UNIQ | CHECK |
|---|---|---|---|---|---|---|
| survived | 生存したかどうか | フラグ | 0=死亡, 1=生存 | |||
| pclass | チケットの等級 | カテゴリ | 1=上層, 2=中級, 3=下層 | |||
| sex | 性別 | カテゴリ | male, female | |||
| age | 年齢 | 数値 | >=0 | |||
| sibsp | 乗船した兄弟、配偶者の数 | 数値 | >=0 | |||
| parch | 乗船した両親、子供の数 | 数値 | >=0 | |||
| fare | 乗船代金 | 数値 | >=0 | |||
| embarked | 出港地 | カテゴリ | C=Cherbourg, Q=Queenstown, S=Southampton | |||
| class | チケットの等級 | カテゴリ | First, Second, Third | |||
| who | 属性 | カテゴリ | man, woman, child | |||
| adult_male | 成人男性かどうか | フラグ | True, False | |||
| deck | 乗船していたデッキ | カテゴリ | A, B, C, D, E, F, G | ✓ | ||
| embark_town | 出港地 | カテゴリ | Cherbourg, Queenstown, Southampton | |||
| alive | 生存したかどうか | フラグ | yes, no | |||
| alone | 一人で乗船したかどうか | フラグ | True, False |
NULL: 欠損値が存在する可能性があるかUNIQ: 重複しない値かCHECK: 満たすべき条件
更に追加情報として、
- データの取得年月日
- データの取得・設計者
- データの取得方法
- データの取得目的
- 利用ライセンス
- 倫理面で配慮すべきこと(個人情報などセンシティブな情報の場合)
を記録しておくと良いです。
バージョン管理
バージョン管理とは、データやドキュメント、ソースコードなどのファイルの更新履歴を管理することです。
Gitなどのバージョン管理システムがありますが、使うことが難しい場合は、適切な名前を付けてバックアップをとることや、README.txtに更新履歴を記録することで対応できます。ただ、Gitは大規模な共同開発だけではなく、小規模な個人プロジェクトにも有用だと考えますので、ぜひこの機会に練習してみると良いと思います。
データの探索
データ探索は、情報可視化と統計的な手法を組み合わせてデータを眺め、データを理解することを指します。「知っていると知っていること」から始めて、「知らないと知っていること」、「知っていると知らないこと」、「知らないと知らないこと」まで確認できると良いです。
統計的な手法では、「知っていると知っていること」と「知らないと知っていること」を確認することができますが、情報可視化は「知っていると知らないこと」と「知らないと知らないこと」により有効です。
データの探索的可視化では、自分が分かるように可視化すればOKです。
6つのアプローチ
- データの分布を見る
- データの関係を見る
- データを縮約する
- データを層別にする
- データを詳細化する
- データを時系列で見る
可視化の方法
- 大きさの比を見る:棒グラフ
- 分布を見る:ヒストグラム、箱ひげ図
- 量的変数の関係を見る:散布図
- 時系列データを見る:折れ線グラフ
- 時系列データの変化と分布を見る:ロウソク足チャート
- 割合を見る:帯グラフ
- 大きさの比とその内訳を見る:積み上げ棒グラフ
- 質的変数の関係を見る:クロス表とヒートマップ
- テキストの内容を見る:ワードクラウド
仮説の設定
ここまでの作業でデータを眺め、データの特徴を各方面から把握できました。それらを踏まえて、最初の問いに対していくつか仮説を立ててみましょう。
仮説とは、「ある現象を合理的に説明するため、仮に立てる説」です。実験・観察などによる検証を通じて、事実と合致すれば定説となります。
データの分析
立てた仮説を検証する形で、データ分析を行います。「データの探索」の段階で使った手法を用いれば十分な場合もありますし、より高度な分析手法を使うことが必要な場合もあります。
- 統計分析の手法
- 要約統計量の記述
- 相関分析
- 帰無仮説検定、など
- テキストマイニングの手法
- ワードカウント
- KWIC (keyword in context) 検索
- 特徴語抽出
- 共起分析
- 階層的クラスタリング、など
- 機械学習の手法
- いろいろ
データの説明
最初の問いへの答えが出たら、自分の問いと答えを誰かに伝えるための情報可視化を行いましょう。 目的と受け手を考えることが最も重要で、その次にデータを視覚的な記号に変換する方法を知ること(これは次週の講義で学びます)が重要です。
目的や受け手について考えるべきことは例えば、
- うまく伝えるためにはどの情報が必要か?
- どのくらい詳しい情報が必要か?
- 受け手が情報を理解するためにはどのくらいの時間が必要か?
- 受け手にとって色や記号は何を意味するか?
- 受け手はどの方向に読むのに慣れているか?
- 受け手はどのような表示に慣れているか?