Happy families are all alike; every unhappy family is unhappy in its own way. (Leo Tolstoy)
Like families, tidy datasets are all alike but every messy dataset is messy in its own way. (Hadley Wickham, 2014)
情報可視化の6ステップ

情報可視化の6ステップのうち、ここでは「データの用意」に含まれるデータの前処理に着目します。
特に、様々な形式で取得され、多くの場合には品質に問題のあるデータを(例えば前回言及した下記のような)、可視化に適したデータに変換するにはどのような指針に従えば良いか、ということを学びます。
- 欠損値:空白のセルは値がないのか(ゼロ/無)、測定しなかったのか(N/A)
- エラー値:明らかにおかしな値(セルがずれているなど)
- 不統一:表記、測定単位、値の形式
- 重複
- 期限切れの値:現時点で不正確だと思われる値(人の年齢など)
- 異常なシステム文字や改行
- 先頭や末尾の余分な空白
- 日付のフォーマット
整然データ(tidy data)
可視化に適したデータとは、すなわち、整然データというものだと本講義では考えたいと思います。
Wickham (2014)1およびWickham, Çetinkaya-Rundel & Grolemund (2023)によると、整然データは以下の4つの条件を満たした表型のデータであり、データの構造(structure)と意味(semantic)が合致しているという特徴を持ちます。
- 1つの列は、1つの変数を表す。
- 1つの行は、1つの観測を表す。
- 1つの表は、1つの観測単位を持つ(異なる観察単位が混ざっていない)。
- 1つのセル(特定の列の特定の行)は、1つの値を表す。
以上の説明だけだと整然データがどんなものかを想像することは難しいので、実例を使って説明します。
ちなみに、整然ではないデータのことを雑然データ(messy data)と言います。
整然データの実例
3名の学生の英語成績を測定したデータセットを考えます。このデータセットでは、アリス、ボブ、チャーリーの3名が10時と15時に1度ずつ受けた英語の成績を記録しています。このデータを3種類の形式で表示したものを以下に示します。いずれも表している内容は全く同じですが、形式のみが異なります。つまり、意味は同じですが、構造が違うということです。
| 氏名 | 10時 | 15時 |
|---|---|---|
| Alice | 90 | 90 |
| Bob | 65 | 80 |
| Charlie | 100 | 95 |
Info
上記形式は、人間にとっては分かりやすい形をしているが、整然ではない。
| 時刻 | Alice | Bob | Charlie |
|---|---|---|---|
| 10時 | 90 | 65 | 100 |
| 15時 | 90 | 80 | 95 |
Info
上記形式も整然ではない。
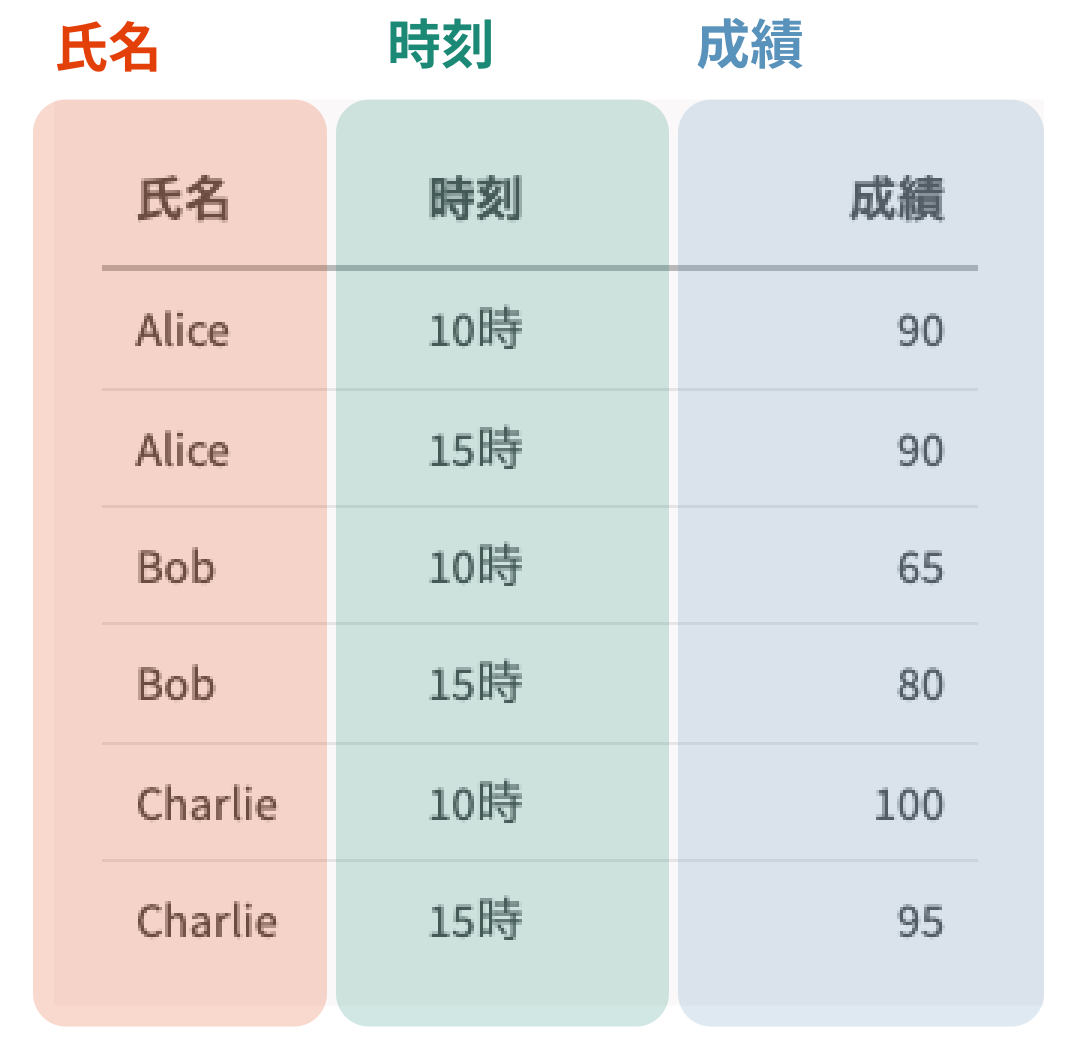
| 氏名 | 時刻 | 成績 |
|---|---|---|
| Alice | 10時 | 90 |
| Alice | 15時 | 90 |
| Bob | 10時 | 65 |
| Bob | 15時 | 80 |
| Charlie | 10時 | 100 |
| Charlie | 15時 | 95 |
Info
上記形式は整然である。
ここで、1つ目と2つ目は整然ではありません(つまり、雑然です)。これに対して最後のものは整然です。なぜそういえるのでしょうか。
変数と列
まず3つのデータの表現形式において変数がどのように表示されているかを確認してみます。このデータには、氏名、時刻、成績という3つの変数があります。

Info
雑然データでは、3つの変数のうち「氏名」は列になっているが、「時刻」は行になっており、「成績」は複数の行と列にまたがっている。
これはつまり、各列が次のように複数の意味を持っているということです。
氏名: 学生の氏名10時: 10時の成績15時: 15時の成績

Info
この雑然データは、上記と比べると「氏名」と「時刻」が入れ替わっている。「時刻」は列になっているが、「氏名」は行になっており、「成績」はやはり複数の行と列にまたがっている。
同様に、2つ目の表の各列も複数の意味を持っている。それぞれが持つ意味は次の通りです。
時刻: テスト実施時刻Alice: Aliceの成績Bob: Bobの成績Charlie: Charlieの成績
こうして見ると、上記2つの表では「氏名」「時刻」「成績」がいずれも意味的には変数であるにも関わらず、その表出された構造は異なっていることが分かります。また、その異なり方が少なくとも2種類あるということも確認できました。更に、上記2つにおいては、整然データの1つ目の条件(「1つの列は、1つの変数を表す」)が満たされていないことも見て取れます。
Info
整然データでは、3つの変数はいずれも列として表現されている。
一方で、3つ目の表ではいずれの変数も1つの列として表されていることが分かります。つまり、この表は整然データの1つ目の条件を満たしていると言えます。
各列の意味を見てみると、それぞれ1つだけ意味を持っていることが分かります。
氏名: 学生の氏名時刻: テスト実施時刻成績: 成績
観測と行
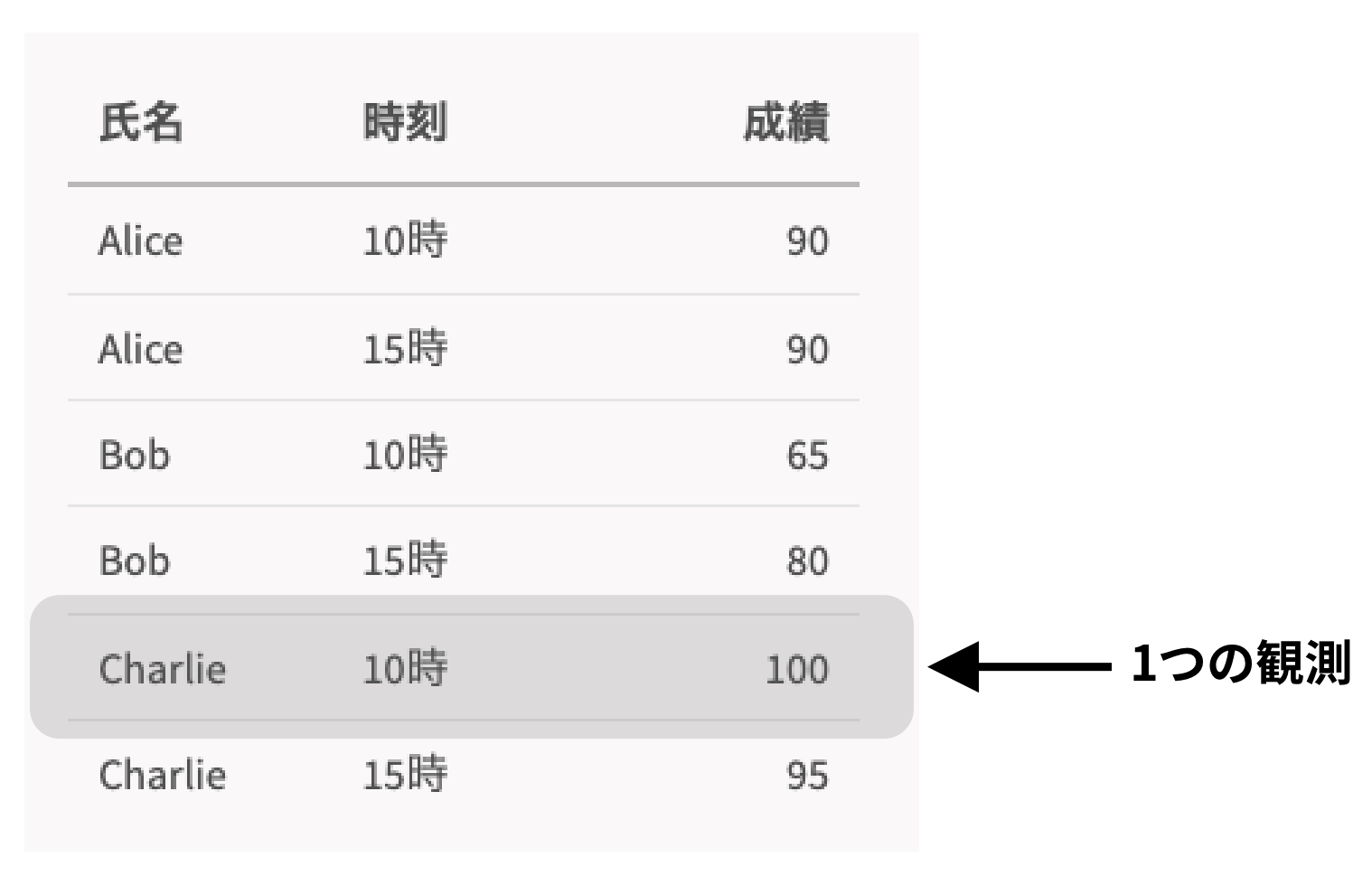
今度は、1つの観測がどのように表されているかを見てみましょう。このデータセットでは、計6個の観測が行われています。

Info
雑然データでは、「Charlieの10時の成績が100点」という1つの観測がばらばらの場所に表現されている。
1つ目の表では、1つの観測に関する情報がばらばらな位置に表現されており、単純な形をしていません。この観測を抽出するコードを書くことはさほど容易ではないはずです。
2つ目の表からも同じことが言えるため、ここでは省略します。
Info
整然データでは、「Charlieの10時の成績が100点」という1つの観測が1つの行で示されている。
一方で、3つ目の表では1つの観測が1つの行という単純な形で示されています。こちらは、整然データの2つ目の条件(1つの行は、1つの観測を表す)を満たしていると言えます。
観測単位と表
整然データの3つ目の条件(1つの表は、1つの観測単位を持つ)は、3つのことを意味します。
- 1つの表に異なる種類の観測が入っていてはいけないということ。例えば、学生の英語の成績を観測した表の中に、教員の給与を観測した表が入っていてはいけない。
- 1つの表に異なる単位の観測が入っていてはいけないということ。例えば、学生の英語の成績を観測した表の中に、学生の英語の成績の合計値が入っていてはいけない。
- 同じ種類の観測が複数の表にまたがっていてはいけないということ。例えば、10時の成績と15時の成績が別々の表に記録されていてはいけない。
いずれの場合を考えても、分析が容易にできないことは想像がつくだろうと思います。
値とセル
整然データの4つ目の条件(1つのセルは、1つの値を表す)は、2つのことを意味します。
- 1つのセルに2つ以上の値が入っていてはいけない。つまり、Aliceの成績が変わらないからといって、次のように時刻をまとめて「10時, 15時」として1つのセルに入れてはいけない。
| 氏名 | 時刻 | 成績 |
|---|---|---|
| Alice | 10時, 15時 | 90 |
| Bob | 10時 | 65 |
| Bob | 15時 | 80 |
| Charlie | 10時 | 100 |
| Charlie | 15時 | 95 |
- 1つの値が2つ以上のセルに分かれていてはいけない。例えば、何らかの2桁のコードがあったおtきに、1桁目と2桁目が別々のセルに格納されるという状況があってはいけない。
構造と意味の合致の重要性
以上に見てきたように、整然データには1つの構造上の単位と1つの意味上の単位が対応しているという特徴があります。例えば、1つの列という構造上の単位が、必ず1つの変数という意味上の単位に対応するということです。
構造と意味が合致していると、可視化に非常に有用です。
私たちが可視化を行う目的は、多くの場合、データにおける意味上の関係を見出すためです。つまり、2列目と3列目にどのように影響するかといった構造上の関係を見たいのではなく、テスト時刻が成績にどのように影響するかといった意味上の関係を知りたいということです。
しかし、実際に可視化や分析プログラムを書く際には、2列名と3列名の差を求めるといったように構造上の単位で記述することが多くあり、意味上の関係を知るためには構造上の関係についてコンピュータに指示を出す必要があります。
ここで構造と意味が合致していないと、人間の思考をコンピュータに理解させるための翻訳をはさむ必要が出てきます。しかし、整然データのように構造と意味が合致していれば、人間が考えた意味をほぼそのまま構造としてコンピュータに渡すことができるということです。
雑然データの利点
以上が整然データの意義ですが、とはいえ整然ではないデータ、つまり雑然データに利点がないわけではありません。人がデータを眺める時には雑然データの方が分かりやすい場合もありますし(例えば1つ目の表で時刻の違いによる成績の変化を確認するなど)、データを紙に印刷をする時にも雑然データの方が紙面を節約できます。
まとめ
人がデータを使う場合には必ずしも整然データが最適とは限りませんが、可視化のためのデータを用意する時、あるいはコンピュータでデータを処理する時には整然データの概念を念頭に置いておくと良いでしょう。